Category:2011-O&C
Please note that the majority of our efforts are contained on the "Discussion" page.
This report was done by Tarjit Komal, Andrew Luczak, Scott Lyons and Seyyed Sajjadpour.
Introduction
This paper is an overview of a theoretical implementation of electronic contract negotiation systems. We begin by exploring the previous work in the field of electronic contract resolution, and we then outline the framework for QUORUM, a proposed system of electronic contract negotiation and mediation with an integrated reputation system.
Focus Of Study
The primary goal of this report is to provide some mechanism for a reliable and automated contract negotiation framework, which system will ideally be functional over a distributed system. As a secondary goal, we discuss a mechanism for observing these contracts; such a mechanism is critical for determining when a contract has been properly fulfilled, which we show is a requirement for the repeatable success of a contract negotiation system.
Background
Automated Contracts
We define an automated contract as any contract between computer systems requiring a minimum of human intervention. Some human effort may be required to define the guidelines by which the system negotiates (i.e. contract with a reliable system with longer wait times as opposed to a less-reliable system with shorter wait times), but the system should be able operate autonomously for the entire contract period.
Assumptions
In order to simplify the problem at hand, we make the following assumptions:
1) All participants in a contract (i.e. the client and the provider), are automated systems (either a single machine, or a group of machines).
2) All machines have a unique universal identifier which is un-spoofable.
3) Any conduct violations arising from a violation of contract parameters can be handled with perfect efficiency and judicial accuracy.
4) Machines have no mobility, in either a physical or network context.
We make these assumptions recognizing that the current implementation of the Internet and other large systems make such a situation impossible (particularly the second assumption wherein identifiers are un-spoofable and universal.
Related Work & Project Basis
The field of electronic contracts has been approached in several different ways, with papers describing several avenues of research; however, no paper we discovered provided a complete system of electronic contract negotiation and validation. Based on what we’ve found in research literature, Service Level Agreements (SLA) are the closest to our proposed system, and were the basis for our framework.
Using the groundwork laid by the following research groups, we look at the problem at a higher level, and focus on an arbitrary network (i.e. a WAN or LAN) that sees computers as citizens. Citizens of this network will get the chance to observe contracts and act as witnesses for other citizens. We will show how SLA-style contract parameters can be used as the benchmarks of a contract verification system, how a reputation system can increase the overall reliability of the contract system, and how a gossiping system can provide an effective propagation of system capabilities.
SLA
Verma, in his paper [1], defines SLA to be “…a formal relationship that exists between a service provider and its customer”. He also mentions some key components of SLAs such as: “a description of the nature of service to be provided”; “the expected performance level of the service, specifically its reliability and responsiveness”; and “the procedure for reporting problems with the service”. These are authentic concerns for any electronic contract. In our system, we adapt Verma’s defined components to be used by each contracted party to verify whether a contract has been fulfilled or not. Verma also discusses various approaches to guaranteeing service, including an insurance approach and an adaptive approach, which can be used by service providers.
Reputation
Groth et al., in their research [2] on the trustworthiness of contracts, propose two key indicators of a contract’s potential reliability: the history of the contracting party, and the similarity of the contract to other successful contracts. Groth et al. also lay out an effective template for contracts (based in turn upon the IST-CONTRACT project) which we use and build upon in our QUORUM system.
Gossiping
In a large network, disseminating information through broadcast updates between everyone in the network will create bandwidth, latency and denial-of-service concerns. Hence, there needs to be some other ways to disseminate information, while avoiding the above mentioned concerns. In their paper[3], Kermarrec et al. define gossiping in distributed systems to be “…the repeated probabilistic exchange of information between two members.” In other words, gossiping is the random dissemination of information, with correct timeouts and periods (depending on the size of the network). In most cases, gossiping would include exchanging lists of information with randomly selected nodes.
In principle, most gossiping algorithms follow the framework provided by Kermarrec et al.:
1) Peer (Node) Selection: Selecting a few random nodes in the network.
2) Data Exchanged: Selecting what information to send to the selected nodes.
3) Data Processing: Once data has been received via gossiping, process that data and decide what action to take.
Gossiping is a common method of dispersing information in distributed systems, and is inspired by real life gossiping. Take, for example, the students in a university department as nodes in your network. Once a new student joins the department, he establishes a friendship with a few other students (nodes) in the department (network). Subsequently, these students may or may not inform others in the department that the new student exists, disclosing the characteristics of the
new student. This gossiping continues, and at the end of a given time period each student has some information about some of the other students in the department; it is highly unlikely that any one student has information regarding every other student in the department, but every student is known by some other student in the department.
Case Study
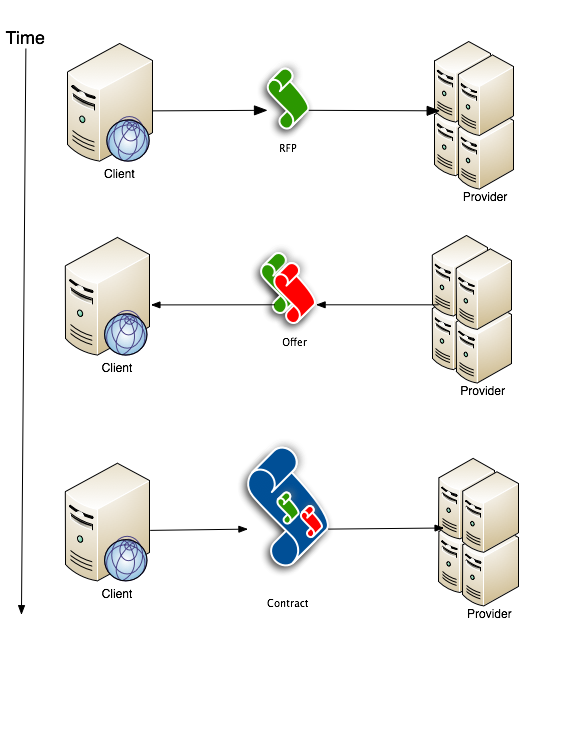
The simplest and most common use case is that of a website suffering from a Denial of Service attack or an unexpected traffic influx. In this example and for all future reference, ForeverAlone.com is the Client and TooMuchBandwidth.net is the Provider. Some automated process or monitor on the Client would be advised of the sudden surge in traffic and would arrange to contact the Provider to request their services. A more detailed look into the request process is detailed below.

Contracts
Contract Template
Groth et al. provide an excellent template for a contract, in the form of a contract schema:

We recognize that this template is simplistic in nature, but it provides an adequate basis for discussion of electronic contracts; any implementation of such a template would need a more detailed structure and syntax. It is worth noting, however, that the IST CONTRACT group, upon whose work Groth et al. based their template, explored the idea of structuring a contract in an XML- style wrapper, which seems a logical progression from the above template.
Contract Formation
The formation of a contract has three general steps:
1) The Client issues a Request For Proposal (RFP)
2) A Provider replies to Client with RFP
3) Both parties agree to terms
Once these three steps have been followed, the contract is set and, assuming the activating condition is met, the normative conditions are put into force.
There exists a problem, however, in enforcing the formation of a contract: some mechanism for verifying the origins of the contract is necessary to prevent the forging of contracts for the purposes of self-promotion. This becomes particularly critical when a reputation system is in effect; the ability to forge a completed contract would be an incredible advantage for a service provider
wishing to boost its reputation (a key component of the QUORUM system, which we discuss in a later section of this paper).
We propose the following procedure for forming a contract:
1) Contract agreement proceeds as above
2) Once the contract has been ratified by the Client and Provider, each provides a copy of the contract template to its neighbors
3) Each neighbor signs the contract as a witness, and propagates the contract across the network as a whole.
This system will produce a group of multiple contracts, each signed by a different witness, but all possessing the same contract identifier (since all copies share the same origin). These contracts can later be collected into a single copy, with a list of all witnesses. Contracts can then be verified based on the presence or absence of certain systems from the witness list. This observation system is built upon a gossiping network protocol, which we describe in more detail later in this paper.
Contract Publication
In order to mitigate fraudulent reputation growth, the proposed witnessing mechanism requires that the contract be propagated through the network. While only a minimum level of detail needs to be shared in order to witness a contract, we recognize the need for a private option, where two systems may forge a contract without any details becoming public knowledge. The QUORUM system provides such an option, though any contract created in private cannot affect reputation; a contract must be witnessed to affect reputation, and a contract must be published to be witnessed.
QUORUM
QUORUM, or Quantifiable Uniform Observation and Reporting of Unmanned Mediation, is our proposed system for electronic contract negotiation and observation on a distributed system. Ideally, QUORUM runs on every machine in the network, acting as a distributed cloud of autonomous observers. In addition to the observers, QUORUM is also comprised of a reputation system, which is built from the history of contracts on the network.
The observers of QUORUM have a single responsibility. When a contract is published, each observer attempts to verify that the normative conditions are being or can be satisfied. Once the expiration condition is reached, each observer reports back to reputation system according to what they believe the final state of the contract is. These observers must operate upon some metric which is appropriate to the contract; metrics for the observers may be a simple binary condition (e.g. has system A provided a piece of information to system B) or a more detailed requirement.
QUORUM Reputation
The QUORUM observers report back on a contract in one of three ways:

The reputation system tracks, for each contracting system on the network, a reputation score based upon the published contract history of that party. Successful contracts increase reputation score, while breached contracts decrease reputation score. Contracts that are voided by both parties or negotiated in private (i.e. without witnesses or QUORUM observation) have a neutral effect on reputation score (though such contracts will still appear in the contract history). This reputation system can then be used by Clients to determine which Provider proposal to accept.
QUORUM Gossip
In order to facilitate the formation of contracts, it is useful to have a regularly updated notion of which systems have certain capabilities. For example, if a particular system is in need of processing time, it needs to be able to quickly determine which providers can offer assistance. To this end, QUORUM requires an inter-system communication network, and so we propose the following gossiping system.
Gossiping in QUORUM
As QUORUM operates, there are four scenarios which involve gossiping: the entrance of a node, the location of available services, the exchange of reputation information, and the detection of network failure. We will address each of these separately. Various gossiping algorithms exist [4], any of which are sufficient for the implementation of QUORUM. Given our current system, we have derived a gossiping method that utilizes some components of existing methods, such as the framework in [3].
Each node will have a list L of other nodes, in this list there exists the identity and known services provided by that node. A node will update entries in L based upon the information it receives through gossip messages.
Entrance
When a node joins a network, it will have the address of two existing nodes on the network. After it joins the network, the two nodes will then randomly assign neighbors to the new node, selecting them from the QUORUM via some algorithm. Depending on the size of the QUORUM, each node will have a fixed h number of neighbors; the number of neighbors and how randomly these neighbors are chosen is an area which needs to be investigated further.
The joining node also sends to its neighbors a list of services that it can provide. Once the neighbouring nodes have received identified and received the services of the incoming node, they can then use a gossiping algorithm of the QUORUM to propagate this information. In turn, the neighbors send their lists to the joining node, making it aware of the various capabilities of the network it has joined.
Search For Services
As we saw in the related work, it is highly unlikely (depending on the size of the QUORUM) for a node to have knowledge of every other node in the system. A given node that is looking for a particular service x, will first look up in his own list L (that has been updated via gossiping messages), and if he cannot find service x with the required reputation, he will then ask around the QUORUM to find the service he is looking for.
Failure Detection
Failure detection in distributed systems is a prominent sub-problem of distributed systems, and has approached by several research groups (see [5-9], as referenced in [5]). Below we present an aggregation of the above efforts, applied to the QUORUM.
Given the neighbor system of QUORUM, each neighbor can expect a gossip message from its neighbors in a period of t seconds. If a neighbor of a node r fails to send such a message, then r will send a heartbeat message to its neighbors (i.e. the pull model [7,8]) asking whether it is alive or not. If r then receives a response, it knows that its neighbor is alive. If r does not receive a response (after enough heartbeat messages to be convinced that his neighbor is dead), then it would remove that node from the list of its neighbors, look for another neighbor, and communicate the node failure (via gossiping messages) to the other members of the QUORUM. Given that this method relies heavily upon the neighbors of a node, it might be prudent to implement an additional failure detection method, such as that found in the work of Hayashibara et al.[9].
Future Work And Conclusion
Moving forward with QUORUM, one main objective would be to attempt an actual implementation of the system according to our specifications. In our research we made several assumptions, one of which was that computers are not mobile. There could be further research done in examining and modifying our QUORUM to allow for system mobility.
References
[1] D.C Verma, Service Level Agreements on IP Networks, Proceedings of the IEEE, vol. 92, pp. 1382- 1388, September 2004.
[2] P. Groth, S. Miles, S. Modgil, N. Oren, M. Luck, G. Yolanda, Determining the Trustworthiness of New Electronic Contracts, Engineering Societies in the Agents World X, 2009.
[3] A. Kermarrec, M. van Steen, Gossiping in Distributed Systems, SIGOPS Oper. Syst. Rev., 41(5):2-7, 2007.
[4] S. Boyd, A. Ghosh, B. Prabhakar, and D. Shah. “Randomized Gossip Algorithms.” IEEE Transactions on Information Theory, 52(6):2508-2530, June 2006
[5] S. Sajjadpour, Failure Detection in Distributed Systems, Distributed Operating Systems course, Carleton University, Winter 2011
[6] R. Van Renesse, Y. Minsky, M. Hayden, A gossip-style failure detection service. In proceeding of the IFIP International Conference on Distributed Systems Platforms and Open Distributed Processing, 1998. The version used here is from 2007.
[7] P. Felber, X. Defago, R. Guerraoui, and P. Oser. Failure detectors as first class objects. In Proceedings of the International Symposium on Distributed Objects and Applications, 1999. The version I used here is from 2002.
[8] N. Hayashibara, A. Cherif, T. Katayama, Failure Detectors for Large-Scale Distributed Systems, In 21st IEEE Symposium of Reliable Distributed Systems (SRDS’ 02). 2002
[9] N. Hayashibara, X. Defago, R. Yared, T. Katayama. The φ accrual failure detector. In Proceedings of the 23rd IEEE International Symposium on Reliable Distributed Systems (SRDS’ 04), pages 55- 75, 2004
Subcategories
This category has the following 2 subcategories, out of 2 total.
Pages in category "2011-O&C"
This category contains only the following page.